import jax
import jax.numpy as jnp
import numpy as np
from functools import partial
import matplotlib.pyplot as plt
plt.rcParams["figure.figsize"] = (12,8)One of the most useful tools in modern machine learning is the ability to automatically differentiate basically anything. Using tools like Jax and torch.autograd you can differentiate through arbitrary programs with control flows, custom data containers and more, the exception being discrete operations like sorting. I’ll try to showcase some fun examples in this post.
Differentiating the Weierstrass Function
A classic example of why analysis is tricky, the Weierstrass function is uniformly continuous but nowhere differentiable. Such a function was thought not to exist until appropriately rigorous mathematical tools were invented.
\[ f(x) = \sum_{n=0}^{\infty} a^n \cos(b^n \pi x) \]
where \(0 < a < 1\), \(b>1\), \(ab > 1\)
Let’s define this function approximation in Jax and try differentiating it anyway.
@jax.jit
def w_term(x, n, a=1/2, b=3):
return a**n * jnp.cos(b**n * jnp.pi * x)
@jax.jit(static_argnames=['n', 'f'])
def weierstrass(x, n, a=1/2, b=3, f = w_term):
res = 0
for n_ in range(n):
res += f(x, n=n_)
return resx = jnp.linspace(-2,2,10000)
plt.plot(x,[weierstrass(x_, n=100, a=1/2, b=3) for x_ in x]);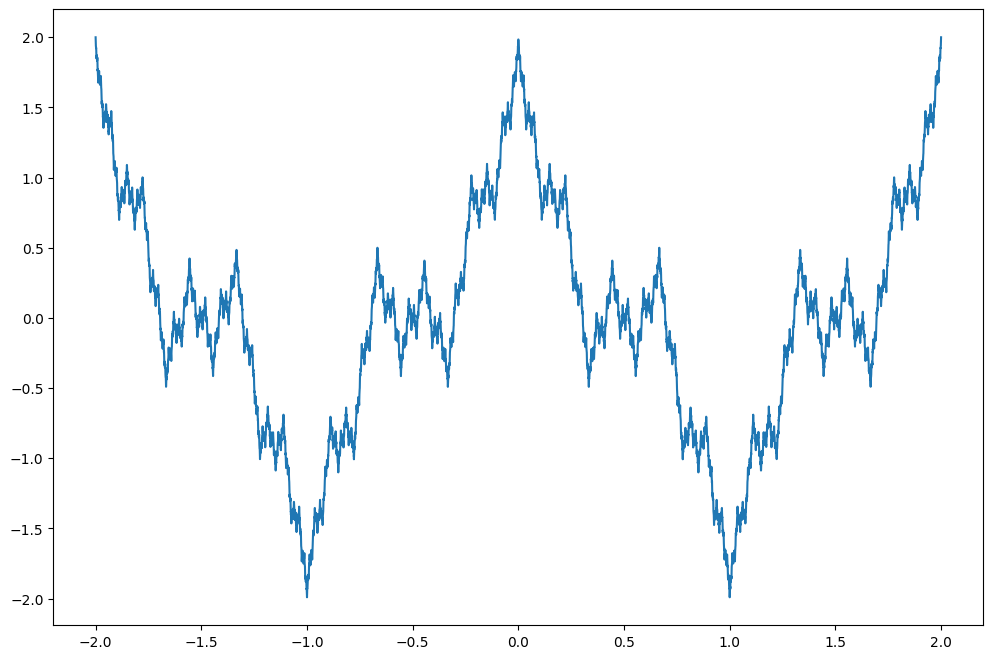
# derivative
w_n = partial(weierstrass, n=100)
plt.plot(x,jax.vmap(jax.grad(w_n))(x));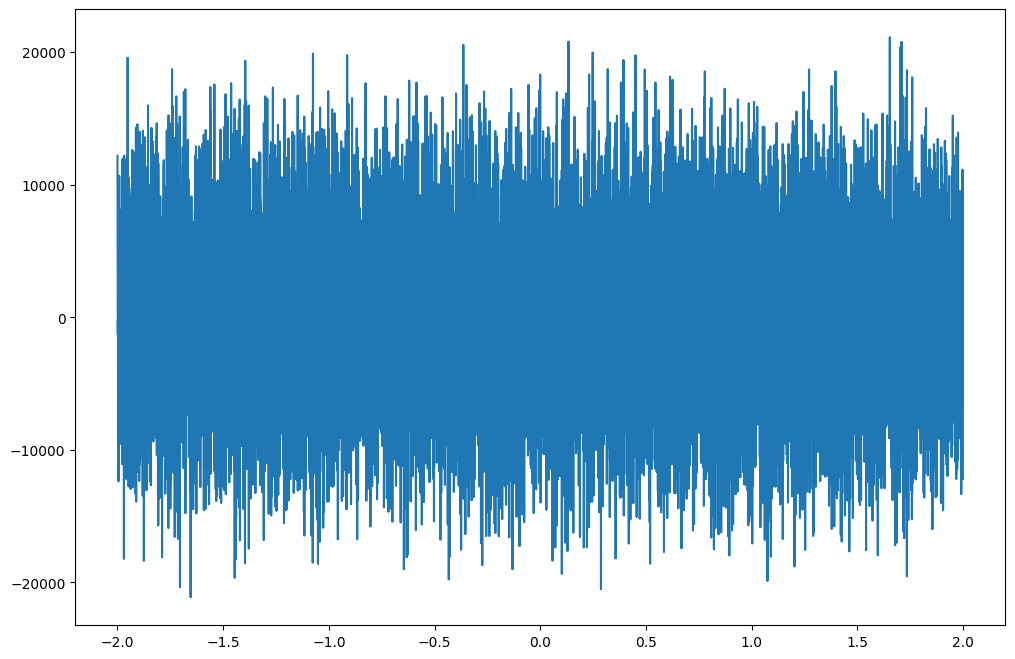
One thing to note here is @jax.jit(static_argnames=['n', 'f']), this is needed since otherwise Jax would treat n, f as fixed variables when compiling. Another catch is that this program slows down considerably with larger n, unrolling python loops probably isn’t very efficient. In production you should probably use jax.lax.scan instead.
We would expect the derivative to blow up for larger n, diverging in the limit. Let’s check.
ns = 10**np.arange(3)
norms = []
for n in ns:
w_n = partial(weierstrass, n=n)
norms.append(jnp.linalg.norm(jax.vmap(jax.grad(w_n))(x),1))
plt.loglog(ns, norms)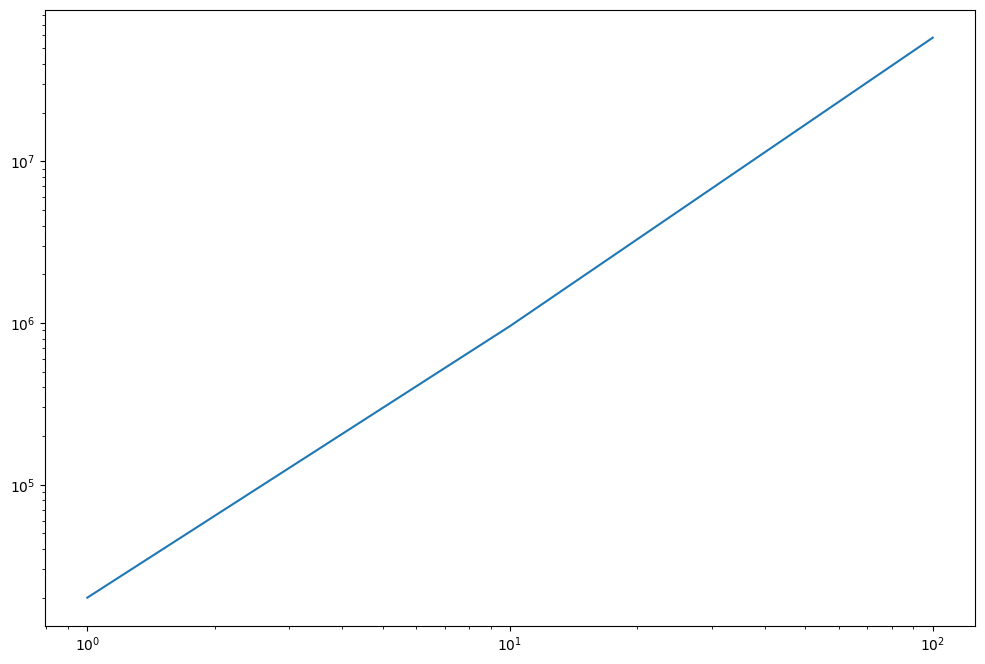
We could also try to switch the orders of summation and differentiation.
ns = 10**np.arange(3)
norms = []
for n in ns:
wt_n = partial(w_term, n=n)
w_n = partial(weierstrass, n=n, f=jax.grad(wt_n))
norms.append(jnp.linalg.norm(jax.vmap(w_n)(x),1))
plt.loglog(ns, norms)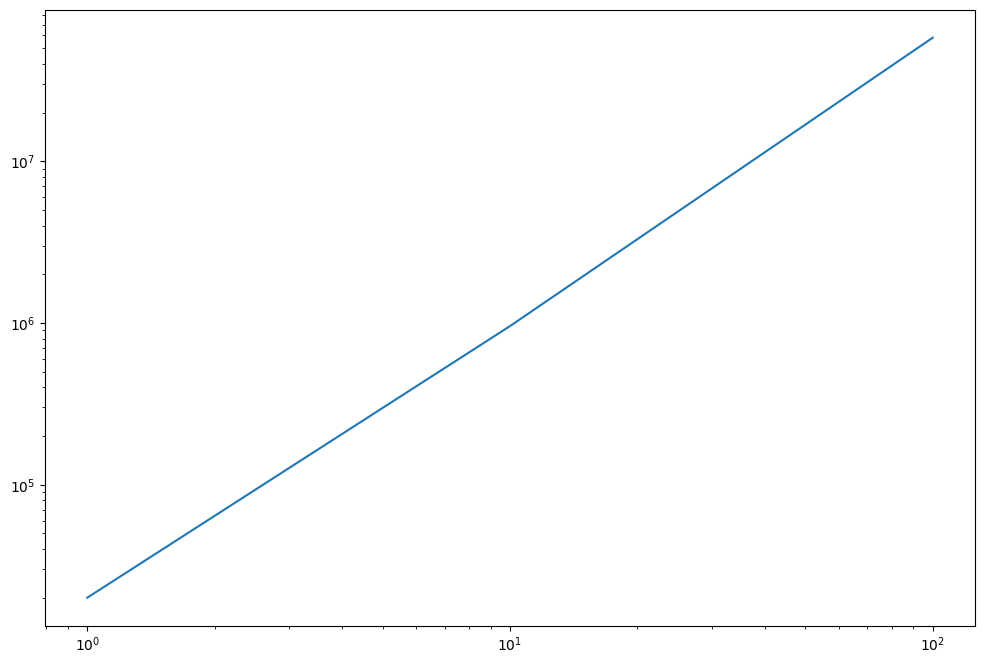
Not too surprisingly this looks exactly the same, we are dealing with finite sums after all.
Portfolio Optimization
Assume we have two correlated financial assets and we want to find the optimal allocation that maximizes the Sharpe ratio \(\frac{\mu}{\sigma}\).
np.random.seed(0)
mu = [.1, .09]
cov = np.random.randn(2,2)
cov = cov.T @ cov
returns = np.random.multivariate_normal(mu, cov, size = 1000)plt.plot(returns.cumsum(axis=0), label=["1", "2"])
plt.legend()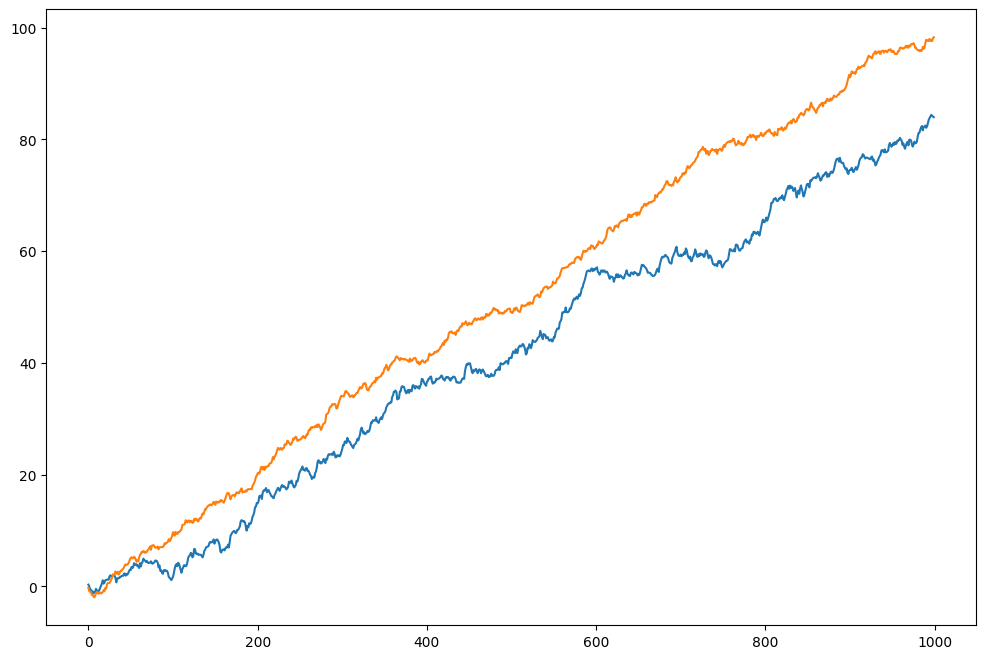
We want to find the optimal weights \(w_i\) to allocate to asset 1 and 2 respectively. Let’s parameterize as \(w_1 = 1 - \theta\), \(w_2 = \theta\).
@jax.jit(static_argnames='returns')
def sharpe_ratio(theta, returns = returns):
r = returns[:,0]*(1-theta) + returns[:,1]*theta
return jnp.mean(r)/jnp.std(r)tt = np.linspace(-3,3, 1000)
plt.plot(tt,jax.vmap(sharpe_ratio)(tt))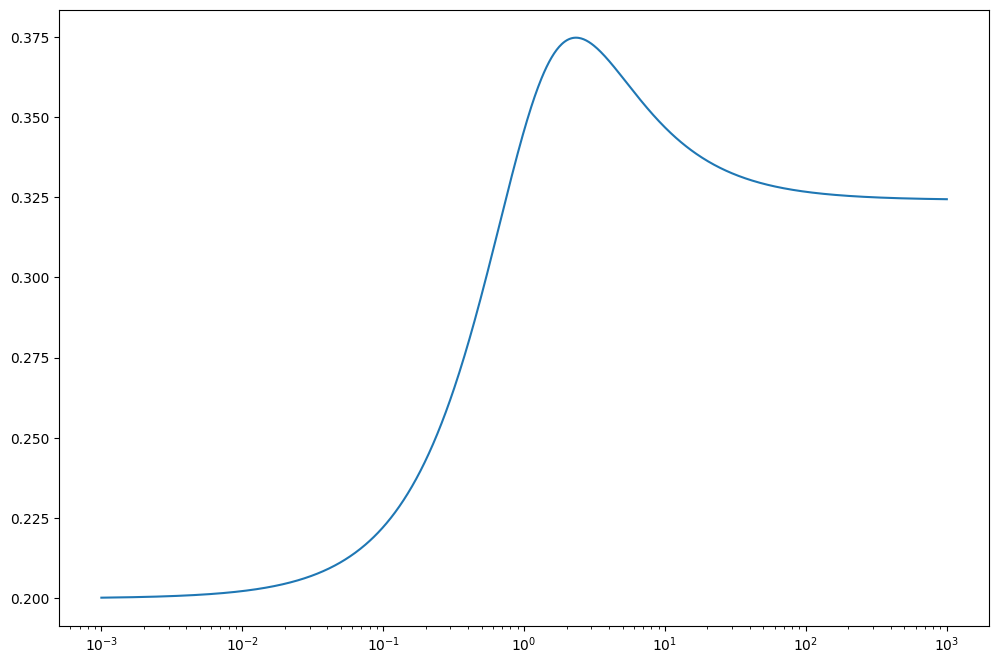
Now that we know we can differentiate pretty much anything we could calculate \(\frac{dS}{d\theta}\) and find the maximum using e.g. Newton–Raphson. Here we just apply an out of the box method from optax, though optimistix may be better suited for this.
import optax
from optax import adam
optimizer = adam(learning_rate = 1e-1)
theta = jnp.array([0.5])
opt_state = optimizer.init(theta)
for _ in range(100):
grads = jax.grad(lambda x : -sharpe_ratio(x))(theta)
updates, opt_state = optimizer.update(grads, opt_state)
theta = optax.apply_updates(theta, updates)
thetaArray([0.13466968], dtype=float32)tt = np.linspace(-3,3, 1000)
plt.plot(tt,jax.vmap(sharpe_ratio)(tt))
plt.axvline(theta, c='red')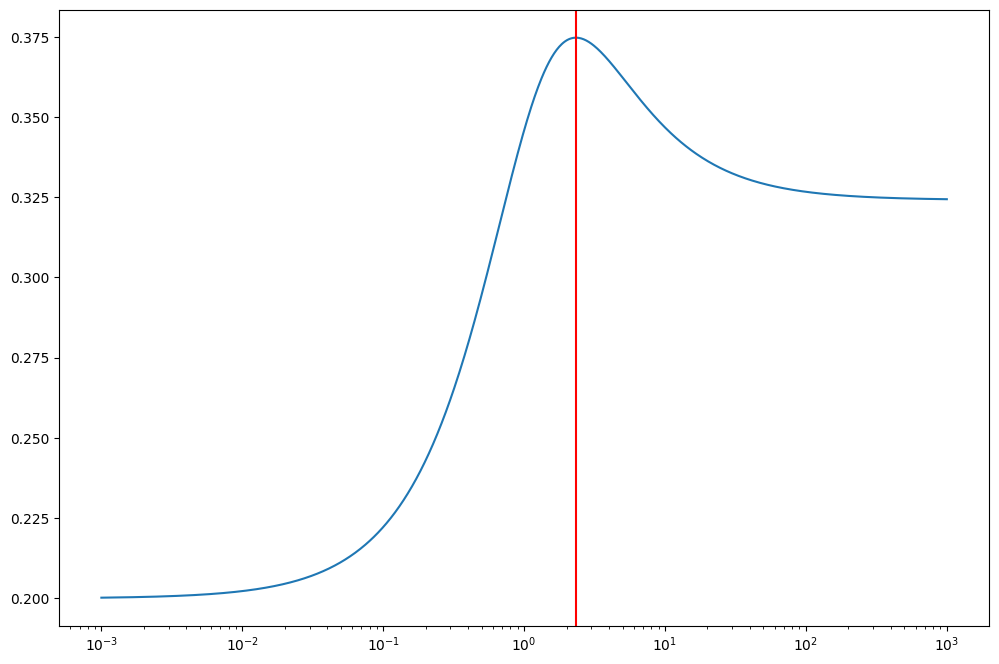
Convenient, in the olden days I might have used an optimization algorithm from e.g. scipy where I would either have to manually supply gradients or rely on black box optimization.
Autodiff opens up for a lot of interesting possibilities, for example differentiating through the solutions of ODEs, simulations, composing neural networks with arbitrary programs etc.
Here are some resources for digging deeper into autodiff.
https://docs.jax.dev/en/latest/notebooks/autodiff_cookbook.html